Introduction:
Conventional data warehousing solution: copy data from transactional DS to a relational DB with schema that's optimized for querying and building multi-dimensional models.
Big Data processing solutions: large volumes of data in multiple formats. Batch loaded or captured in real-time streams and stored in a data lake from which distributed processing engines like Apache Spark are used to process it.
Data warehousing Architecture:
-
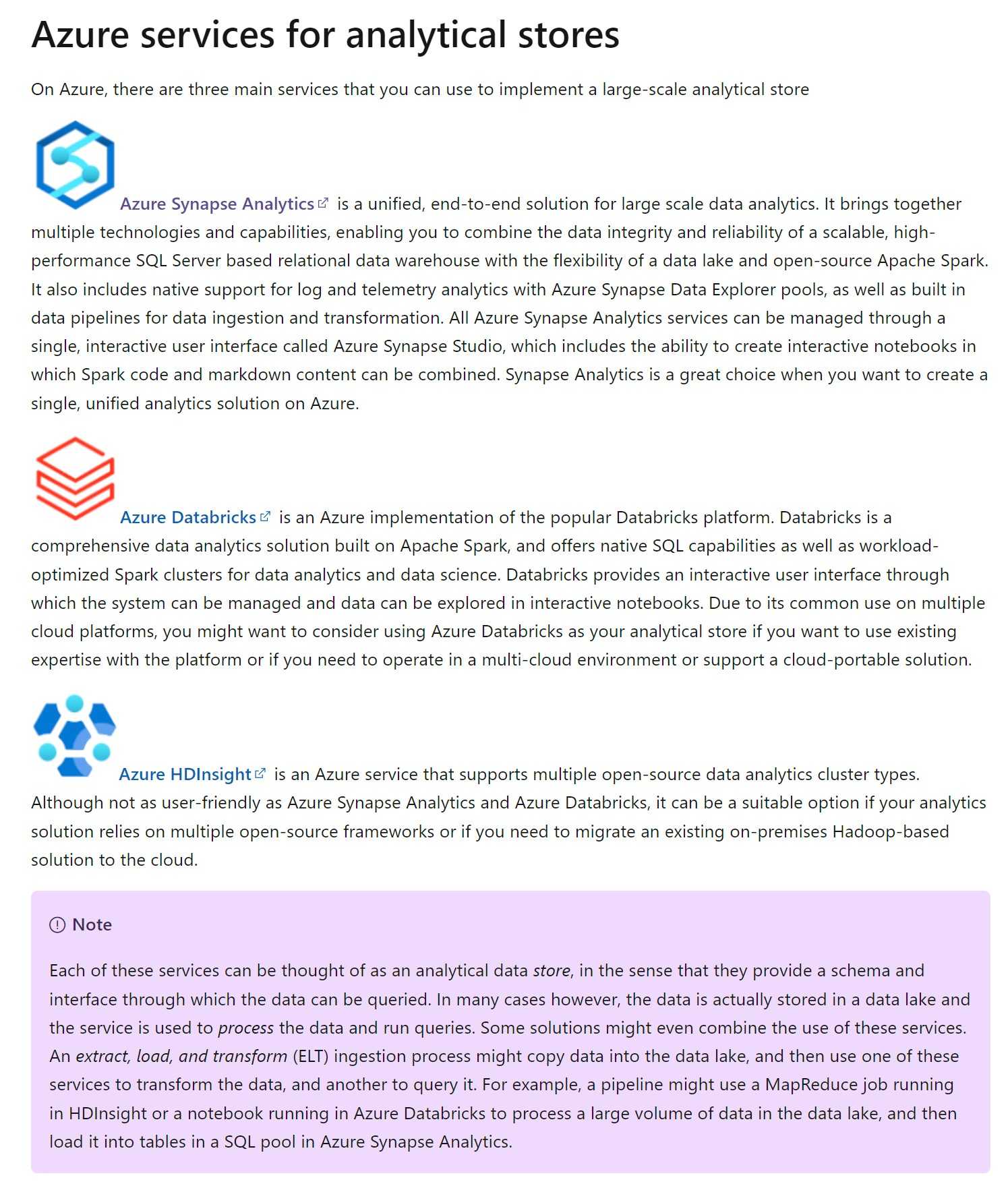
Data ingestion and processing – data from one or more transactional data stores, files, real-time streams, or other sources are loaded into data stores for large scale analytics (data lake, relational data warehouse). The load operation usually involves an extract, transform, and load (ETL) or extract, load, and transform (ELT) process in which the data is cleaned, filtered, and restructured for analysis. In ETL processes, the data is transformed before being loaded into an analytical store, while in an ELT process the data is copied to the store and then transformed. Either way, the resulting data structure is optimized for analytical queries. The data processing is often performed by distributed systems that can process high volumes of data in parallel using multi-node clusters.
-
Analytical data store – data stores for large scale analytics include relational data warehouses file-system based data lakes, and hybrid architectures that combine features of data warehouses and data lakes.
-
Analytical data model – data model(s) that pre-aggregate the data to make it easier to produce reports, dashboards, and interactive visualisations. Often these data model are described as cubes, in which numeric data values are aggregated across dimensions. The model encapsulates the relationships between the data values and dimensional entities to support "drill-up/drill-down" analysis.
-
Data visualization – data analysts consume data from analytical models, and directly from analytical stores to create reports, dashboards, and other visualizations. Additionally, users in an organization who may not be technology professionals might perform self-service data analysis and reporting. The visualizations from the data show trends, comparisons, and key performance indicators (KPIs) for a business or other organization, and can take the form of printed reports, graphs and charts in documents or PowerPoint presentations, web-based dashboards, and interactive environments in which users can explore data visually.
Data ingestion pipelines
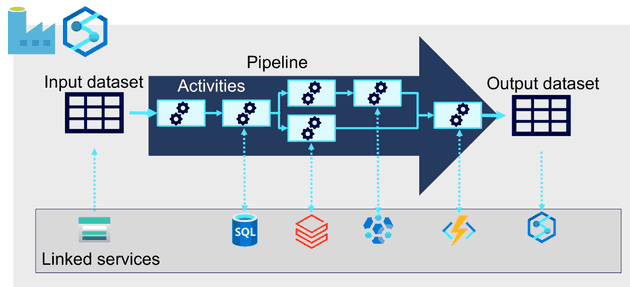 Large-scale data ingestion can be implemented by creating pipelines that orchestrate the ETL processes using Azure Data Factory, or you can use the same pipeline engine in Azure Synapse Analytics if you want to manage all of the components of your data warehousing solution in a unified workspace. In either case, pipelines consist of one or more activities that operate on data. An input dataset provides the source data, and activities can be defined as a data flow that incrementally manipulates the data until an output dataset is produced. Pipelines use linked services to load and process data – enabling you to use the right technology for each step of the workflow. For example, you might use an Azure Blob Store linked service to ingest the input dataset, and then use services such as Azure SQL Database to run a stored procedure that looks up related data values, before running a data processing task on Azure Databricks or Azure HDInsight, or apply custom logic using an Azure Function. Finally, you can save the output dataset in a linked service such as Azure Synapse Analytics. Pipelines can also include some built-in activities, which don’t require a linked service.
Large-scale data ingestion can be implemented by creating pipelines that orchestrate the ETL processes using Azure Data Factory, or you can use the same pipeline engine in Azure Synapse Analytics if you want to manage all of the components of your data warehousing solution in a unified workspace. In either case, pipelines consist of one or more activities that operate on data. An input dataset provides the source data, and activities can be defined as a data flow that incrementally manipulates the data until an output dataset is produced. Pipelines use linked services to load and process data – enabling you to use the right technology for each step of the workflow. For example, you might use an Azure Blob Store linked service to ingest the input dataset, and then use services such as Azure SQL Database to run a stored procedure that looks up related data values, before running a data processing task on Azure Databricks or Azure HDInsight, or apply custom logic using an Azure Function. Finally, you can save the output dataset in a linked service such as Azure Synapse Analytics. Pipelines can also include some built-in activities, which don’t require a linked service.
Analytical data stores
Data warehouses:
A data warehouse is a relational database in which the data is stored in a schema that is optimized for data analytics rather than transactional workloads. Commonly, the data from a transactional store is transformed into a schema in which numeric values are stored in central fact tables, which are related to one or more dimension tables that represent entities by which the data can be aggregated. For example a fact table might contain sales order data, which can be aggregated by customer, product, store, and time dimensions (enabling you, for example, to easily find monthly total sales revenue by product for each store). This kind of fact and dimension table schema is called a star schema; though it's often extended into a snowflake schema by adding additional tables related to the dimension tables to represent dimensional hierarchies (for example, product might be related to product categories). A data warehouse is a great choice when you have transactional data that can be organized into a structured schema of tables, and you want to use SQL to query them.
Data lakes: A data lake is a file store, usually on a distributed file system for high performance data access. Technologies like Spark or Hadoop are often used to process queries on the stored files and return data for reporting and analytics. These systems often apply a schema-on-read approach to define tabular schemas on semi-structured data files at the point where the data is read for analysis, without applying constraints when it's stored. Data lakes are great for supporting a mix of structured, semi-structured, and even unstructured data that you want to analyse without the need for schema enforcement when the data is written to the store.
Hybrid approaches: You can use a hybrid approach that combines features of data lakes and data warehouses in a lake database or data lakehouse. The raw data is stored as files in a data lake, and a relational storage layer abstracts the underlying files and expose them as tables, which can be queried using SQL. SQL pools in Azure Synapse Analytics include PolyBase, which enables you to define external tables based on files in a datalake (and other sources) and query them using SQL. Synapse Analytics also supports a Lake Database approach in which you can use database templates to define the relational schema of your data warehouse, while storing the underlying data in data lake storage – separating the storage and compute for your data warehousing solution. Data lakehouses are a relatively new approach in Spark-based systems, and are enabled through technologies like Delta Lake; which adds relational storage capabilities to Spark, so you can define tables that enforce schemas and transactional consistency, support batch-loaded and streaming data sources, and provide a SQL API for querying.